R 语言教程
R 数据重塑
合并数据框
R 语言合并数据框使用 merge() 函数。
merge() 函数语法格式如下:
# S3 方法
merge(x, y, …)
# data.frame 的 S3 方法
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE,
incomparables = NULL, …)常用参数说明:
x, y: 数据框
by, by.x, by.y:指定两个数据框中匹配列名称,默认情况下使用两个数据框中相同列名称。
all:逻辑值; all = L 是 all.x = L 和 all.y = L 的简写,L 可以是 TRUE 或 FALSE。
all.x:逻辑值,默认为 FALSE。如果为 TRUE, 显示 x 中匹配的行,即便 y 中没有对应匹配的行,y 中没有匹配的行用 NA 来表示。
all.y:逻辑值,默认为 FALSE。如果为 TRUE, 显示 y 中匹配的行,即便 x 中没有对应匹配的行,x 中没有匹配的行用 NA 来表示。
sort:逻辑值,是否对列进行排序。
merge() 函数和 SQL 的 JOIN 功能很相似:
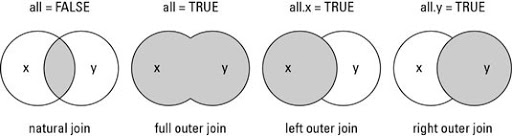
Natural join 或 INNER JOIN:如果表中有至少一个匹配,则返回行
Left outer join 或 LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
Right outer join 或 RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
Full outer join 或 FULL JOIN:只要其中一个表中存在匹配,则返回行
# data frame 1
df1 = data.frame(SiteId = c(1:6), Site = c("Google","Nhooo","Taobao","Facebook","Zhihu","Weibo"))
# data frame 2
df2 = data.frame(SiteId = c(2, 4, 6, 7, 8), Country = c("CN","USA","CN","USA","IN"))
# INNER JOIN
df1 = merge(x=df1,y=df2,by="SiteId")
print("----- INNER JOIN -----")
print(df1)
# FULL JOIN
df2 = merge(x=df1,y=df2,by="SiteId",all=TRUE)
print("----- FULL JOIN -----")
print(df2)
# LEFT JOIN
df3 = merge(x=df1,y=df2,by="SiteId",all.x=TRUE)
print("----- LEFT JOIN -----")
print(df3)
# RIGHT JOIN
df4 = merge(x=df1,y=df2,by="SiteId",all.y=TRUE)
print("----- RIGHT JOIN -----")
print(df4)执行以上代码输出结果为:
[1] "----- INNER JOIN -----" SiteId Site Country 1 2 Nhooo CN 2 4 Facebook USA 3 6 Weibo CN [1] "----- FULL JOIN -----" SiteId Site Country.x Country.y 1 2 Nhooo CN CN 2 4 Facebook USA USA 3 6 Weibo CN CN 4 7 <NA> <NA> USA 5 8 <NA> <NA> IN [1] "----- LEFT JOIN -----" SiteId Site.x Country Site.y Country.x Country.y 1 2 Nhooo CN Nhooo CN CN 2 4 Facebook USA Facebook USA USA 3 6 Weibo CN Weibo CN CN [1] "----- RIGHT JOIN -----" SiteId Site.x Country Site.y Country.x Country.y 1 2 Nhooo CN Nhooo CN CN 2 4 Facebook USA Facebook USA USA 3 6 Weibo CN Weibo CN CN 4 7 <NA> <NA> <NA> <NA> USA 5 8 <NA> <NA> <NA> <NA> IN
数据整合和拆分
R 语言使用 melt() 和 cast() 函数来对数据进行整合和拆分。
melt() :宽格式数据转化成长格式。
cast() :长格式数据转化成宽格式。
下图很好展示来 melt() 和 cast() 函数的功能(后面示例会详细说明):

melt() 将数据集的每个列堆叠到一个列中,函数语法格式:
melt(data, ..., na.rm = FALSE, value.name = "value")
参数说明:
data:数据集。
...:传递给其他方法或来自其他方法的其他参数。
na.rm:是否删除数据集中的 NA 值。
value.name 变量名称,用于存储值。
进行以下操作之前,我们先安装依赖包:
# 安装库,MASS 包含很多统计相关的函数,工具和数据集
install.packages("MASS", repos = "https://mirrors.ustc.edu.cn/CRAN/")
# melt() 和 cast() 函数需要对库
install.packages("reshape2", repos = "https://mirrors.ustc.edu.cn/CRAN/")
install.packages("reshape", repos = "https://mirrors.ustc.edu.cn/CRAN/")测试示例:
# 载入库
library(MASS)
library(reshape2)
library(reshape)
# 创建数据框
id<- c(1, 1, 2, 2)
time <- c(1, 2, 1, 2)
x1 <- c(5, 3, 6, 2)
x2 <- c(6, 5, 1, 4)
mydata <- data.frame(id, time, x1, x2)
# 原始数据框
cat("原始数据框:\n")
print(mydata)
# 整合
md <- melt(mydata, id = c("id","time"))
cat("\n整合后:\n")
print(md)执行以上代码输出结果为:
原始数据框: id time x1 x2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4 整合后: id time variable value 1 1 1 x1 5 2 1 2 x1 3 3 2 1 x1 6 4 2 2 x1 2 5 1 1 x2 6 6 1 2 x2 5 7 2 1 x2 1 8 2 2 x2 4
cast 函数用于对合并对数据框进行还原,dcast() 返回数据框,acast() 返回一个向量/矩阵/数组。
cast() 函数语法格式:
dcast( data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data) ) acast( data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data) )
参数说明:
data:合并的数据框。
formula:重塑的数据的格式,类似 x ~ y 格式,x 为行标签,y 为列标签 。
fun.aggregate:聚合函数,用于对 value 值进行处理。
margins:变量名称的向量(可以包含"grand\_col" 和 "grand\_row"),用于计算边距,设置 TURE 计算所有边距。
subset:对结果进行条件筛选,格式类似 subset = .(variable=="length")。
drop:是否保留默认值。
value.var:后面跟要处理的字段。
# 载入库
library(MASS)
library(reshape2)
library(reshape)
# 创建数据框
id<- c(1, 1, 2, 2)
time <- c(1, 2, 1, 2)
x1 <- c(5, 3, 6, 2)
x2 <- c(6, 5, 1, 4)
mydata <- data.frame(id, time, x1, x2)
# 整合
md <- melt(mydata, id = c("id","time"))
# Print recasted dataset using cast() function
cast.data <- cast(md, id~variable, mean)
print(cast.data)
cat("\n")
time.cast <- cast(md, time~variable, mean)
print(time.cast)
cat("\n")
id.time <- cast(md, id~time, mean)
print(id.time)
cat("\n")
id.time.cast <- cast(md, id+time~variable)
print(id.time.cast)
cat("\n")
id.variable.time <- cast(md, id+variable~time)
print(id.variable.time)
cat("\n")
id.variable.time2 <- cast(md, id~variable+time)
print(id.variable.time2)执行以上代码输出结果为:
id x1 x2 1 1 4 5.5 2 2 4 2.5 time x1 x2 1 1 5.5 3.5 2 2 2.5 4.5 id 1 2 1 1 5.5 4 2 2 3.5 3 id time x1 x2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4 id variable 1 2 1 1 x1 5 3 2 1 x2 6 5 3 2 x1 6 2 4 2 x2 1 4 id x1_1 x1_2 x2_1 x2_2 1 1 5 3 6 5 2 2 6 2 1 4